publications
2026
- Arxiv
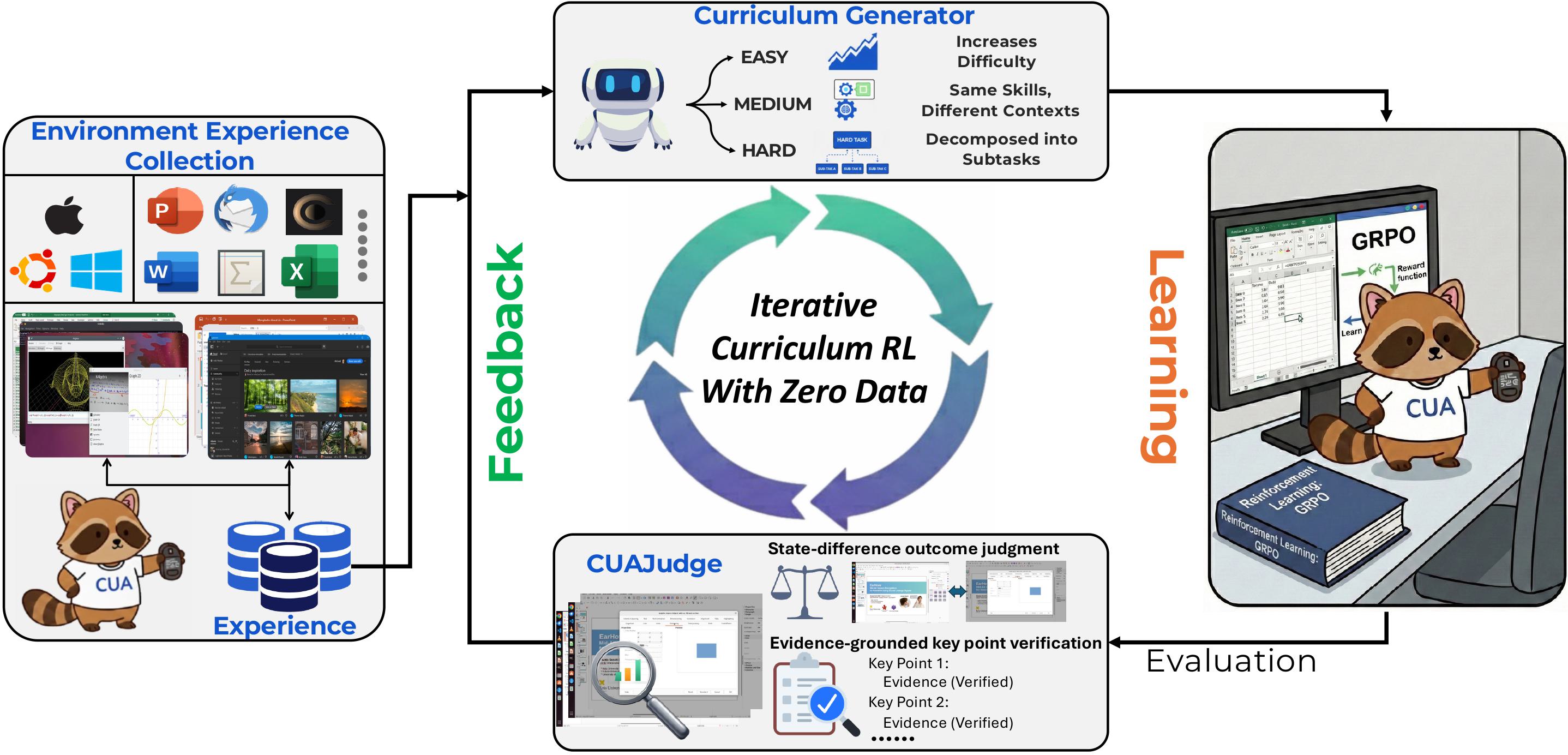 Autonomous Continual Learning of Computer-Use Agents for Environment AdaptationTianci Xue, Zeyi Liao, Tianneng Shi, and 5 more authors2026
Autonomous Continual Learning of Computer-Use Agents for Environment AdaptationTianci Xue, Zeyi Liao, Tianneng Shi, and 5 more authors2026Real-world digital environments are highly diverse and dynamic. These characteristics cause agents to frequently encounter unseen scenarios and distribution shifts, making continual learning in specific environments essential for computer-use agents (CUAs). However, a key challenge lies in obtaining high-quality and environment-grounded agent data without relying on costly human annotation. In this work, we introduce ACuRL, an Autonomous Curriculum Reinforcement Learning framework that continually adapts agents to specific environments with zero human data. The agent first explores target environments to acquire initial experiences. During subsequent iterative training, a curriculum task generator leverages these experiences together with feedback from the previous iteration to synthesize new tasks tailored for the agent’s current capabilities. To provide reliable reward signals, we introduce CUAJudge, a robust automatic evaluator for CUAs that achieves 93% agreement with human judgments. Empirically, our method effectively enables both intra-environment and cross-environment continual learning, yielding 4-22% performance gains without catastrophic forgetting on existing environments. Further analyses show highly sparse updates (e.g., 20% parameters), which helps explain the effective and robust adaptation.
@article{xue2026autonomouscontinuallearningcomputeruse, title = {Autonomous Continual Learning of Computer-Use Agents for Environment Adaptation}, author = {Xue, Tianci and Liao, Zeyi and Shi, Tianneng and Wang, Zilu and Zhang, Kai and Song, Dawn and Su, Yu and Sun, Huan}, year = {2026}, }
2025
- ArxivHolistic Agent Leaderboard: The Missing Infrastructure for AI Agent EvaluationarXiv preprint arXiv:2510.11977, 2025
@article{xue2023parameter, title = {Holistic Agent Leaderboard: The Missing Infrastructure for AI Agent Evaluation}, author = {}, journal = {arXiv preprint arXiv:2510.11977}, year = {2025}, } - Arxiv
 Agent Learning via Early ExperienceKai Zhang, Xiangchao Chen, Bo Liu, and 27 more authorsarXiv preprint arXiv:2510.08558, 2025
Agent Learning via Early ExperienceKai Zhang, Xiangchao Chen, Bo Liu, and 27 more authorsarXiv preprint arXiv:2510.08558, 2025A long-term goal of language agents is to learn and improve through their own experience, ultimately outperforming humans in complex, real-world tasks. However, training agents from experience data with reinforcement learning remains difficult in many environments, which either lack verifiable rewards (e.g., websites) or require inefficient long-horizon rollouts (e.g., multi-turn tool use). As a result, most current agents rely on supervised fine-tuning on expert data, which is challenging to scale and generalizes poorly. This limitation stems from the nature of expert demonstrations: they capture only a narrow range of scenarios and expose the agent to limited environment diversity. We address this limitation with a middle-ground paradigm we call early experience: interaction data generated by the agent’s own actions, where the resulting future states serve as supervision without reward signals. Within this paradigm we study two strategies of using such data: (1) Implicit world modeling, which uses collected states to ground the policy in environment dynamics; and (2) Self-reflection, where the agent learns from its suboptimal actions to improve reasoning and decision-making. We evaluate across eight diverse environments and multiple model families. Our approaches consistently improve effectiveness and out-of-domain generalization, highlighting the value of early experience. Moreover, in environments with verifiable rewards, our results provide promising signals that early experience offers a strong foundation for subsequent reinforcement learning, positioning it as a practical bridge between imitation learning and fully experience-driven agents.
@article{zhang2025agentlearningearlyexperience, title = {Agent Learning via Early Experience}, author = {Zhang, Kai and Chen, Xiangchao and Liu, Bo and Xue, Tianci and Liao, Zeyi and Liu, Zhihan and Wang, Xiyao and Ning, Yuting and Chen, Zhaorun and Fu, Xiaohan and Xie, Jian and Sun, Yuxuan and Gou, Boyu and Qi, Qi and Meng, Zihang and Yang, Jianwei and Zhang, Ning and Li, Xian and Shah, Ashish and Huynh, Dat and Li, Hengduo and Yang, Zi and Cao, Sara and Jang, Lawrence and Zhou, Shuyan and Zhu, Jiacheng and Sun, Huan and Weston, Jason and Su, Yu and Wu, Yifan}, journal = {arXiv preprint arXiv:2510.08558}, year = {2025}, } - COLM
 An illusion of progress? assessing the current state of web agentsTianci Xue, Weijian Qi, Tianneng Shi, and 5 more authorsIn Conference on Language Modeling, 2025
An illusion of progress? assessing the current state of web agentsTianci Xue, Weijian Qi, Tianneng Shi, and 5 more authorsIn Conference on Language Modeling, 2025As digitalization and cloud technologies evolve, the web is becoming increasingly important in the modern society. Autonomous web agents based on large language models (LLMs) hold a great potential in work automation. It is therefore important to accurately measure and monitor the progression of their capabilities. In this work, we conduct a comprehensive and rigorous assessment of the current state of web agents. Our results depict a very different picture of the competency of current agents, suggesting over-optimism in previously reported results. This gap can be attributed to shortcomings in existing benchmarks. We introduce Online-Mind2Web, an online evaluation benchmark consisting of 300 diverse and realistic tasks spanning 136 websites. It enables us to evaluate web agents under a setting that approximates how real users use these agents. To facilitate more scalable evaluation and development, we also develop a novel LLM-as-a-Judge automatic evaluation method and show that it can achieve around 85% agreement with human judgment, substantially higher than existing methods. Finally, we present the first comprehensive comparative analysis of current web agents, highlighting both their strengths and limitations to inspire future research.
@inproceedings{xue2025illusion, title = {An illusion of progress? assessing the current state of web agents}, author = {Xue, Tianci and Qi, Weijian and Shi, Tianneng and Song, Chan Hee and Gou, Boyu and Song, Dawn and Sun, Huan and Su, Yu}, booktitle = {Conference on Language Modeling}, year = {2025}, } - NeurIPS D&BMind2Web 2: Evaluating Agentic Search with Agent-as-a-JudgeBoyu Gou, Zanming Huang, Yuting Ning, and 8 more authorsThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025, 2025
@article{gou2025mind2web, title = {Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge}, author = {Gou, Boyu and Huang, Zanming and Ning, Yuting and Gu, Yu and Lin, Michael and Qi, Weijian and Kopanev, Andrei and Yu, Botao and Guti{\'e}rrez, Bernal Jim{\'e}nez and Shu, Yiheng and others}, journal = {The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025}, year = {2025}, }
2024
- ACL
 PACIT: Unlocking the Power of Examples for Better In-Context Instruction TuningTianci Xue, Ziqi Wang, Yixia Li, and 2 more authorsIn Findings of the Association for Computational Linguistics: ACL 2024, Aug 2024
PACIT: Unlocking the Power of Examples for Better In-Context Instruction TuningTianci Xue, Ziqi Wang, Yixia Li, and 2 more authorsIn Findings of the Association for Computational Linguistics: ACL 2024, Aug 2024Instruction tuning enhances the instruction following ability of large language models by finetuning with supervised instruction data. Previous work proposes in-context instruction tuning (ICIT) where specific positive or negative examples are incorporated into the prompt for better performance. In this work, we propose PACIT, a simple and effective in-context instruction tuning method, inspired by the pedagogical concept of desirable difficulty. The PACIT method unlocks the power of examples by encouraging the model to actively learn to grasp the distinctions between the positive and negative examples instead of merely reading. The model is expected to first verify the correctness of the provided example according to the task description, which is then set as the condition for generating a better response to the task instance. Our extensive experiments prove the effectiveness of PACIT, outperforming ICIT baseline on both in-domain and out-domain tasks up to 9.16 and 3.14 average ROUGE-L scores, respectively. Moreover, PACIT can notably enhance the performance of instruction tuning even when all positive and negative examples are generated with a self-instruct method.
@inproceedings{xue-etal-2024-pacit, title = {{PACIT}: Unlocking the Power of Examples for Better In-Context Instruction Tuning}, author = {Xue, Tianci and Wang, Ziqi and Li, Yixia and Chen, Yun and Chen, Guanhua}, editor = {Ku, Lun-Wei and Martins, Andre and Srikumar, Vivek}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2024}, month = aug, year = {2024}, address = {Bangkok, Thailand}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.findings-acl.36/}, doi = {10.18653/v1/2024.findings-acl.36}, pages = {654--665}, } - TMLRIs your llm secretly a world model of the internet? model-based planning for web agentsYu Gu, Kai Zhang, Yuting Ning, and 8 more authorsTransactions on Machine Learning Research, 2025, Aug 2024
@article{gu2024your, title = {Is your llm secretly a world model of the internet? model-based planning for web agents}, author = {Gu, Yu and Zhang, Kai and Ning, Yuting and Zheng, Boyuan and Gou, Boyu and Xue, Tianci and Chang, Cheng and Srivastava, Sanjari and Xie, Yanan and Qi, Peng and others}, journal = {Transactions on Machine Learning Research, 2025}, year = {2024}, }
2023
- Arxiv
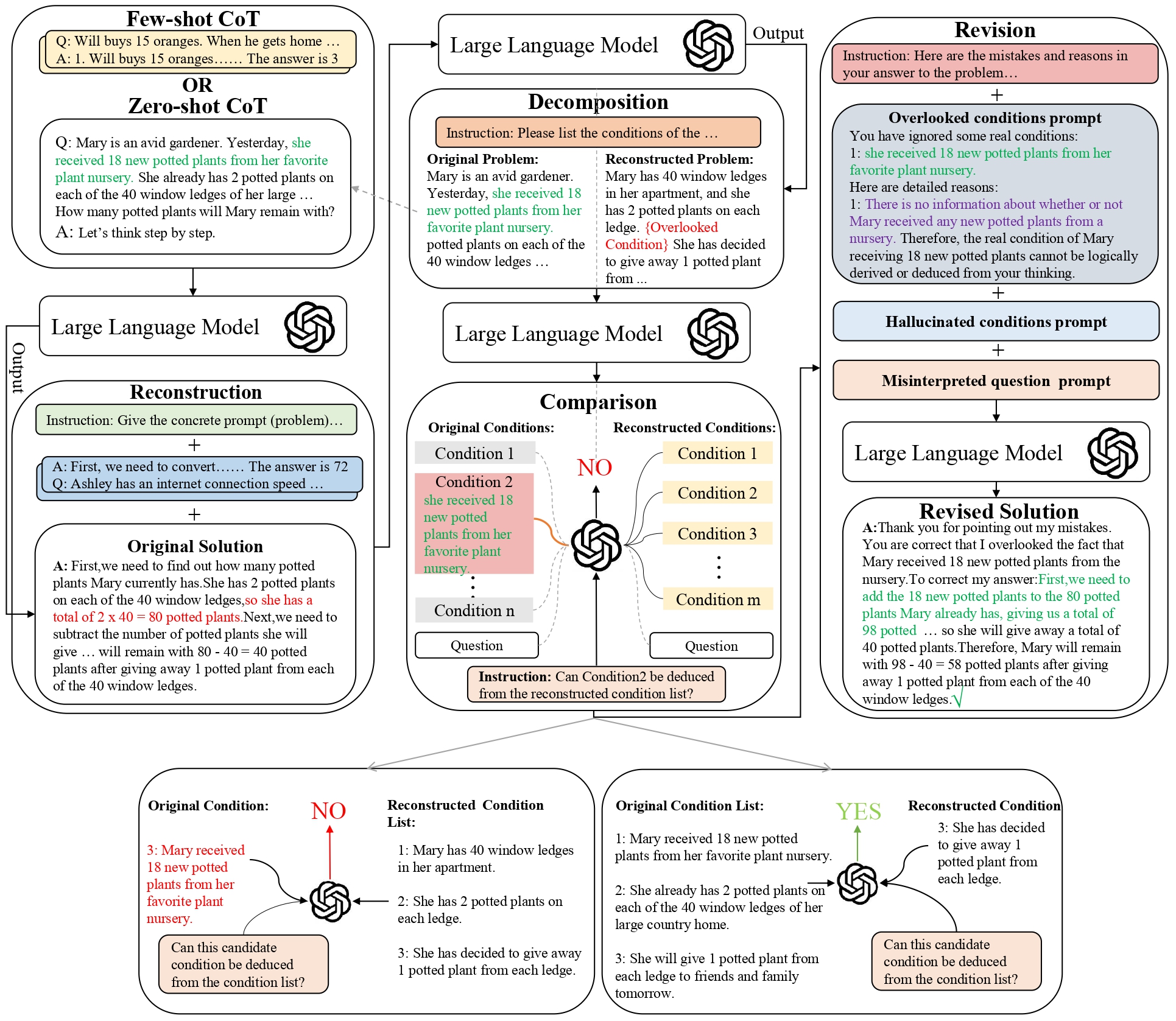 Rcot: Detecting and rectifying factual inconsistency in reasoning by reversing chain-of-thoughtTianci Xue, Ziqi Wang, Zhenhailong Wang, and 3 more authorsarXiv preprint arXiv:2305.11499, Aug 2023
Rcot: Detecting and rectifying factual inconsistency in reasoning by reversing chain-of-thoughtTianci Xue, Ziqi Wang, Zhenhailong Wang, and 3 more authorsarXiv preprint arXiv:2305.11499, Aug 2023Large language Models (LLMs) have achieved promising performance on arithmetic reasoning tasks by incorporating step-by-step chain-of-thought (CoT) prompting. However, LLMs face challenges in maintaining factual consistency during reasoning, exhibiting tendencies to condition overlooking, question misinterpretation, and condition hallucination over given problems. Existing methods use coarse-grained feedback (e.g., whether the answer is correct) to improve factual consistency. In this work, we propose RCoT (Reversing Chain-of-Thought), a novel method to improve LLMs’ reasoning abilities by automatically detecting and rectifying factual inconsistency in LLMs, generated solutions. To detect factual inconsistency, RCoT first asks LLMs to reconstruct the problem based on generated solutions. Then fine-grained comparisons between the original problem and the reconstructed problem expose the factual inconsistency in the original solutions. To rectify the solution, RCoT formulates detected factual inconsistency into fine-grained feedback to guide LLMs in revising solutions. Experimental results demonstrate improvements of RCoT over standard CoT, Self-Consistency and Self-Refine across seven arithmetic datasets. Moreover, we find that manually written fine-grained feedback can dramatically improve LLMs’ reasoning abilities (e.g., ChatGPT reaches 94.6% accuracy on GSM8K), encouraging the community to further explore the fine-grained feedback generation methods.
@article{xue2023rcot, title = {Rcot: Detecting and rectifying factual inconsistency in reasoning by reversing chain-of-thought}, author = {Xue, Tianci and Wang, Ziqi and Wang, Zhenhailong and Han, Chi and Yu, Pengfei and Ji, Heng}, journal = {arXiv preprint arXiv:2305.11499}, year = {2023}, } - ArxivParameter-efficient tuning helps language model alignmentTianci Xue, Ziqi Wang, and Heng JiarXiv preprint arXiv:2310.00819, Aug 2023
@article{xue2023parametes, title = {Parameter-efficient tuning helps language model alignment}, author = {Xue, Tianci and Wang, Ziqi and Ji, Heng}, journal = {arXiv preprint arXiv:2310.00819}, year = {2023}, }